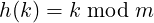
[This page is auto-generated; please prefer to read the article’s PDF Form.]
In the Division Method of hashing, the hash-function h(k) is simply:
|
|
It can be proved that, if the input keys k are randomly uniformly distributed over any set of mn consecutive integers (for some positive integer n), then their mod m values too will be uniformly distributed over ℤm = {0,1,2,…,m − 1}. That is, their hash-values h(k) will be uniformly distributed over ℤm. In this situation with input keys, m being a prime or not has no importance.
But often it is not possible to be certain that the input keys are such random. They all, or a subset of them, may exhibit some patterns. For example, a subset of input keys may follow a “linear-pattern”, where each key has the form b + ai, where a and b are fixed integers and i acts as the variable integer. Such pattern can emerge due to a variety of reasons. For example:
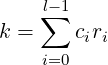 |
Say, a group of such keys have all components in common, except one component say cn. Then, these keys will have k in form b + (rn)cn, where b is fixed and component cn varies.
A common example of this is strings, where each character is a component ci, last character being c0. Here, 0 ≤ ci ≤ 127 and each ri can be chosen ri, where r = 128.
Suppose a group of string keys have their last few, say n, chars common. Then every such string will have k in form b + (rn)i, where b is the numeric value of the n common chars, b = ∑ i=0n−1ciri. For example, addresses often have their last part as country name, which would be common among many addresses. Similarly, email-addresses have their last part, the domain, quite common.
Copyright © 2021 Nitin Verma. All rights reserved.